
While faceted filters improve user experience, they can greatly increase your URL count, waste crawl budget, and create duplicate content. UX improvements with limited indexation using canonicals, noindex, follow, and AJAX/SSR patterns are explained in this guide.
What is Faceted Navigation?
Definition and Purpose
Faceted navigation is the filtering tool you often overlook while shopping online. It appears as a sidebar or menu on e-commerce sites, media vaults, and other product-heavy platforms. People call it guided navigation, filtered search, or faceted search; however, they all mean the same thing. It lets you zoom in on what you want using “facets” like size, shade, and make. Consequently, the system quietly powers a smoother user experience (UX).
Everyday Examples
Picture you’re on a clothing site. You check “Medium,” then “Blue.” As a result, you get an instant mini-catalog of blue Medium dresses. If you switch to tech, you might filter laptops by “Dell” and “500 to 1,000.” The list updates in a heartbeat. This is more nimble than a slow drop-down or a one-size-fits-all category. In short, the hunt feels easy, so customers find the perfect blue dress and buy it. Therefore, they stay longer, and the site racks up more sales.
The SEO Problem with Faceted Navigation
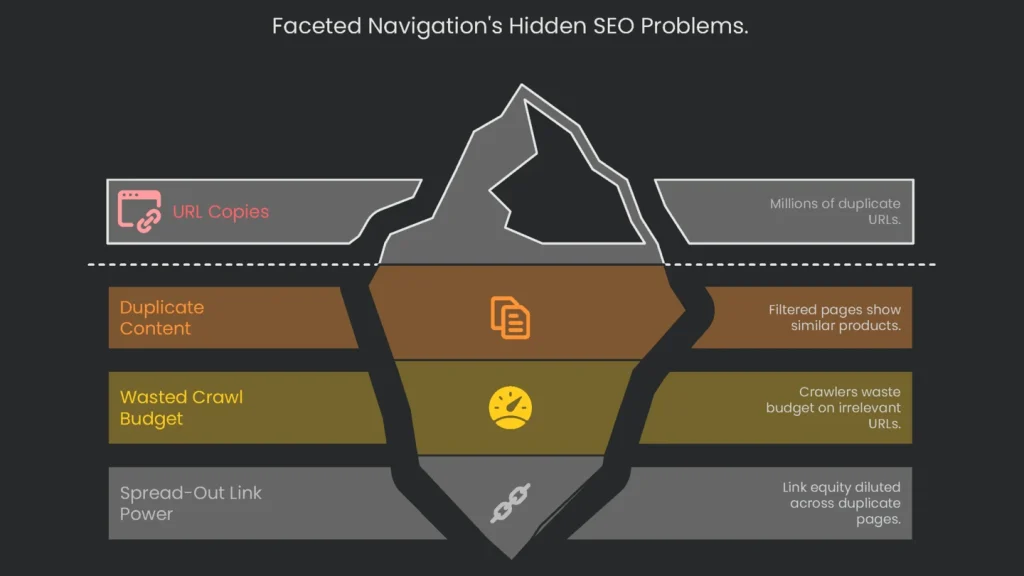
Why It Hurts SEO
Faceted navigation is fantastic for visitors. However, from an SEO point of view, it can create a big mess. Each time a shopper stacks filters, the site sends them to a fresh URL—like this:
https://www.example.com/t-shirts?color=blue&size=large. With only a handful of filters, you can rack up millions of URL copies. Consequently, three big SEO headaches appear.
Three Core Issues
- Duplicate and Thin Content: Most filtered pages show nearly the same products as the main category. Therefore, search engines treat them as a ton of duplicate pages.
duplicate pages that don’t add fresh value confuse which page should rank. As a result, pages fight for the same keywords, known as keyword cannibalization. Also, engines may see the site as thin or low-quality.
- Wasted Crawl Budget: Search engines send a limited “crawl budget.” When crawlers hit floods of near-identical filter URLs, that budget gets burned on pages that don’t matter.
Googlebot then delays higher-priority content. Consequently, newly launched products or updated pages may take longer to get crawled and indexed.
- Spread-Out Link Power: Link equity spreads across countless duplicates. Instead of one powerful category page, you get thousands of weak pages. Therefore, rankings suffer.
This tug-of-war between UX and SEO creates a persistent headache. However, headaches also reveal solutions. Most filtered URLs add clutter, yet a few precise combos match real demand—often long, buy-intent queries like “black Nike running shoes for men.” As a result, a smart audit can sweep waste aside and let those “killer” combos shine.
Don’t Go for Band-Aids
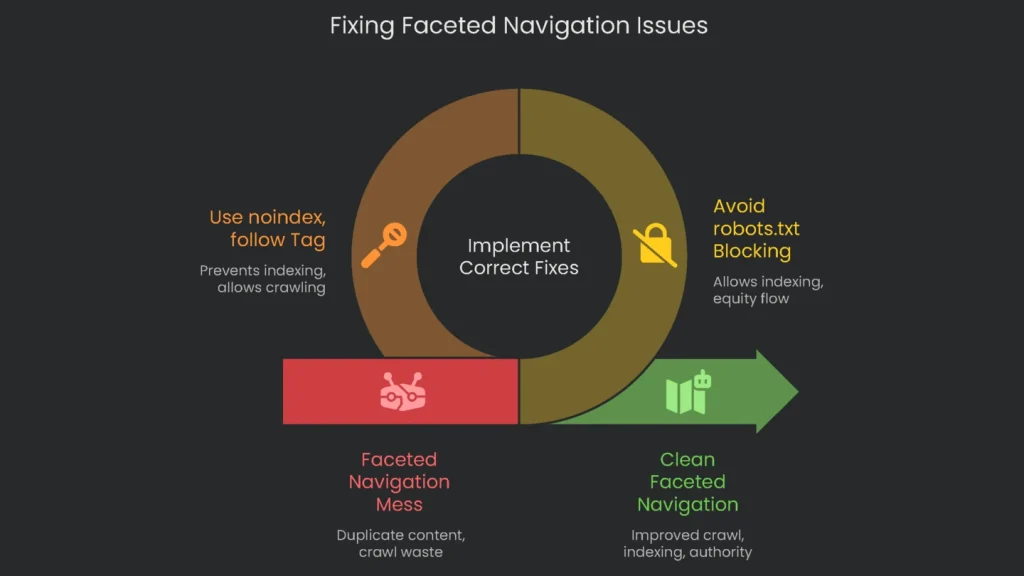
Site owners often grab the first “fix” they hear for faceted nav mess. However, quick patches can create more duplicate piles. The root problem isn’t only technical. It’s a misunderstanding of how Google crawls, indexes, and shares authority.
Blocking URLs in robots.txt
One huge mistake is stopping crawlers with the
robots.txt file for every parameter-based URL. It sounds smart at first. However, it backfires for three reasons:
- Stops Crawling, Not Indexing: Blocking via robots.txt says, “Don’t walk through this door,” yet engines can still index the URL if an external site links to it.
- Creates an Ugly Search Result: Blocking leads to “Indexed, but blocked” in Google Search Console. Consequently, a bare URL may appear with no title or snippet.
- Stops Link Equity Flow: The blocked page can’t pass authority. As a result, category pages starve product pages, and the whole site pays the price.
Applying noindex the Wrong Way
Using the noindex tag for every filtered page sounds smart. The intent is clear: keep crawlers visiting but keep pages out of results. However, the tag must be set correctly.
<meta name=”robots” content=”noindex, nofollow”> is a common misstep. The nofollow directive tells crawlers to skip every link. Consequently, the filtered page becomes a dead end, and link authority can’t reach key listings.
Switching to noindex, follow helps, yet it doesn’t cut crawl waste immediately. Google must visit each filtered page to read the tag. Therefore, results clean up over time, but crawl budget isn’t infinite.
Three Modern Solutions for Faceted Navigation

Use “Crawl, Noindex, Follow”
Want a neat way to keep clutter out while guiding link power? This method does exactly that.
- How It Works: Let search engines crawl filtered pages, but add <meta name=”robots” content=”noindex, follow”> in the head.
- Why It Works: “noindex” hides the page from results, while “follow” lets equity flow through links. Consequently, priority pages still gain strength.
- When to Use It: Use it for sites cluttered with faceted filters. The tag removes pages from results quickly, while authority keeps flowing.
- Think About This First: Google must crawl to see the tag. Therefore, crawl savings arrive later, not instantly.
Using Canonical Tags
Going the canonical route is usually the top pick. Instead of simply hiding pages, you point Google to the primary page you want ranking. As a result, signals from copies consolidate onto the best URL.
- How It Works: Add a rel=”canonical” link in the <head> of each filtered page, pointing to the clean version. For example, for https://www.example.com/laptops?brand=dell use:
<link rel=”canonical” href=”https://www.example.com/laptops” />
- Why It’s Effective: The canonical tag says, “This is a copy; credit the main page.” Consequently, clutter drops, and ranking power consolidates. Over time, Google may also crawl these variants less.
- When to Use It: Most e-commerce stores—especially those with built-in support—should use canonicals. It scales cleanly and solves indexing and ranking in one move.
- A Key Insight: rel=”canonical” is a strong hint, not a command. If a filtered page differs a lot, Google can ignore the tag and index it anyway.
Use AJAX and JavaScript
This solution is sleek and user-approved. It sidesteps messy URL problems before they appear.
- How It Works: When you tap a filter, JavaScript—specifically AJAX—fetches products and refreshes the section without reloading the URL. Because the address stays the same, engines don’t see new parameters.
- SEO Note: Heavy client-side rendering can hide data from crawlers. Therefore, use server-side rendering so both visitors and bots get full content. The JavaScript layer can then filter and sort views.
- Making URLs Easy to Share: If you rely only on AJAX, users may struggle with back buttons or shareable links. Two techniques fix this:
- Use the History API—pushState—to rewrite the address to a clean path like
/laptops/brand-dellwithout reloading. You can route that path to a real server page or add a rel=”canonical” link. - Or append a hash like
/laptops#brand=dell. Crawlers usually ignore fragments, so reports stay clean, yet users get a tidy, shareable link.
- Use the History API—pushState—to rewrite the address to a clean path like
- When to Use It: Large, custom e-commerce sites with the right team and servers benefit most. Consequently, users stay happy and SEO stays clean.
How to Pick the Right Approach
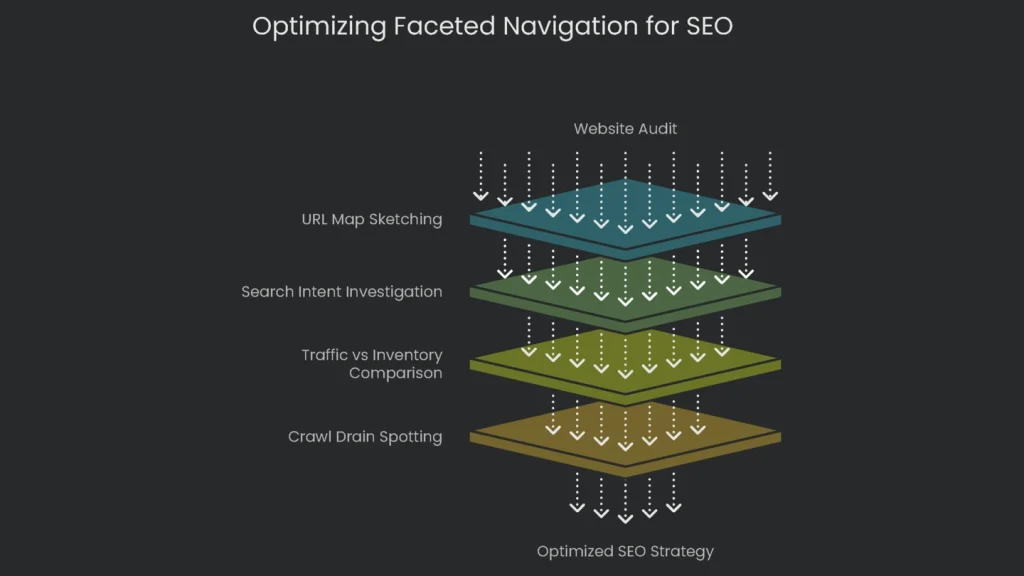
Audit Your Website
Before you dive into fixes, step back. See how your site really works, and spot leaks worth sealing.
- Sketch the URL Map: Trace how filters generate parameters. Note how many filters can stack. Consequently, you’ll grasp the problem’s size.
- Investigate Search Intent: Not every filtered page is junk. Run a keyword search. For example, “best compact rice cooker under $50” could justify an indexable landing page.
- Compare Traffic with Inventory: Check analytics for filtered links bringing organic visitors. Then compare with your catalog. If a page shows one item or none, keep it out of search.
- Spot the Crawl Drain: Review Crawl Stats in Search Console and server logs. If filter URLs dominate hits, you’re burning budget. Therefore, tighten things up.
Comparing the Three Solutions
Once the audit wraps up, use this table to weigh each option.
| Feature | Solution 1: noindex, follow | Solution 2: rel=”canonical” | Solution 3: AJAX with SSR |
| Indexing Control | Strong: The tag removes extras quickly. Great for tidy shops. | Medium: A solid signal that usually works, yet Google may ignore it for large variations. | Very Strong: Prevents new duplicate pages from appearing. |
| Crawl Budget Impact | Low: Bots must crawl once to read the tag; later it eases. | Medium: Similar at first; over time Google may crawl less. | High: Blocks duplicate URLs upfront, saving budget immediately. |
| Link Authority | High: “follow” lets authority flow to product pages. | Very High: Consolidates signals to the main category page. | Very High: No duplicates means no dilution. |
| Setup Difficulty | Low–Medium: Add a meta tag to parameterized URLs. | Low: Most platforms support canonicals out of the box. | High: Requires JavaScript and server configuration. |
Which Strategy is Best for You?
- Scenario A: Best for Most Sites—Canonicalization
For the great majority of e-commerce sites,
rel=”canonical” is the default move. It balances ease and power. It tackles duplicate content and protects link equity without a full dev sprint. Therefore, start here unless a rare edge case appears.
- Scenario B: Best for Big Clean-Up—noindex, follow
When Google has already indexed hundreds of problematic filtered URLs, use a heavy-duty fix. The
<meta name=”robots” content=”noindex, follow”> tag pulls these pages out of results faster than waiting for canonicals alone. Consequently, the index tidies up quickly.
- Scenario C: Best for Smooth Browsing—AJAX with SSR
For enterprise-grade stores with strong dev teams, AJAX backed by Server-Side Rendering (SSR) is the gold standard. Customers enjoy speed. Search engines get fully rendered pages. As a result, crawl budget goes to meaningful URLs. Yes, it costs more, but the payoff beats slow pages and missed rankings.
Conclusion: Turn Facets into Favors
Key Takeaways
Faceted navigation maintenance is now central for e-commerce teams. Ignore it, and authority leaks while rivals pass you. Tackle it, and your store runs like a machine. Consequently, you convert crawl budget and UX into rankings that matter.
Next Steps
Mass-produced low-value URLs drain crawl budget and spread link equity thin. Blocking in robots.txt or pairing noindex with nofollow often backfires. Instead, use modern tactics.
Choose noindex + follow, rel=”canonical”, or AJAX with SSR based on your audit. The right pick depends on search demand, traffic patterns, and your technical setup.
An effective plan does more than prevent disaster. It turns navigation into a growth engine. By guiding crawlers to priority content, you pool signals and strengthen category pages. Finally, by purposefully indexing high-impact filtered pages, you capture ready-to-buy traffic.
At Technicalseoservice, we love tricky tech puzzles. We run a full check-up, lay out a game plan, and ship the fixes. If you’re ready to unlock your store’s true power, we’re the team to call.
Implementation steps
- Write down every filter and URL parameter, then note which pairs create fresh or duplicate pages.
- On the low-quality facet results, add rel=canonical pointing back to the main category page.
- Thin pages that get few visitors should have meta robots “noindex,follow” to still pass page strength.
- Limit facet combinations that create new URLs; keep only the most valuable ones visible in the HTML.
- Check crawl stats and server logs to ensure search bots crawl fewer newly-parametered URLs
Frequently Asked Questions
Why can facets hurt SEO?
They churn out endless parameter URLs, using up crawl budget and adding duplicate content.
Should I block facets in robots.txt?
That’s usually a no. Use noindex,follow or a canonical instead. Blocking in robots.txt won’t remove the pages from the index.
When should a facet be indexable?
When it has real search demand and the inventory is big and stable.
What’s a safe default control?
Self-canonical to the main category, then add meta noindex,follow to the low-value facets.
How do I cut crawl waste?
Limit combinations, go AJAX with SSR for speed, and link only the high-value filters.